RelevanceIQ: Grounded Product Search over 568K Reviews
RelevanceIQ: Grounded Product Search
Most RAG demos are a vector store and a prompt. RelevanceIQ is a production-grade hybrid retrieval and citation-grounded RAG system over the Amazon Fine Food Reviews corpus (568K reviews / 74K products), where every design choice is measured, benchmarked, and served through a live FastAPI stack.
BM25 · dense retrieval · cross-encoder reranking · query reformulation · evidence-grounded generation, with a stage-by-stage visual UI.
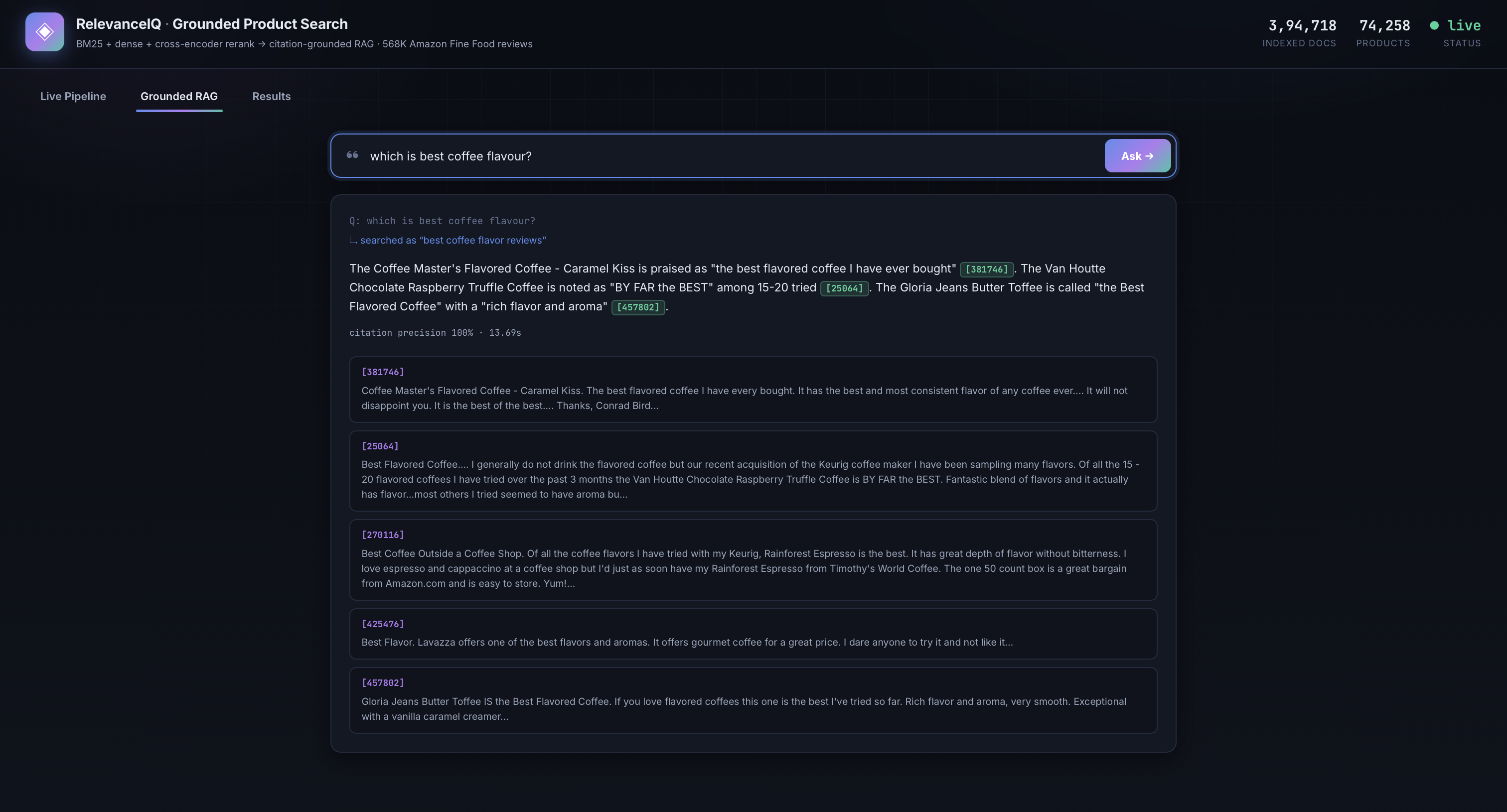
Every claim is cited to a retrieved review (100% citation precision). The Live Pipeline view streams each retrieval stage as it runs.
Why This Exists
This is a deliberately engineered retrieval system: every design choice is measured against a labeled evaluation set, the serving path is benchmarked, and failure modes are visible rather than hidden.
It answers three questions, with numbers:
- Does hybrid retrieval + reranking beat a strong lexical baseline, and by how much?
- Does citation grounding reduce hallucination in RAG, measurably?
- Can it be served at production latency, and what is the honest p95?
The stack combines OpenSearch, FAISS, sentence-transformers, Ollama, FastAPI, and MLflow into a fully local, end-to-end search and RAG platform.
Key Results
All numbers are measured, reproducible (make eval | rag | bench), and tracked in MLflow. Evaluation uses 100 queries with 3,625 LLM-judged graded relevance labels.
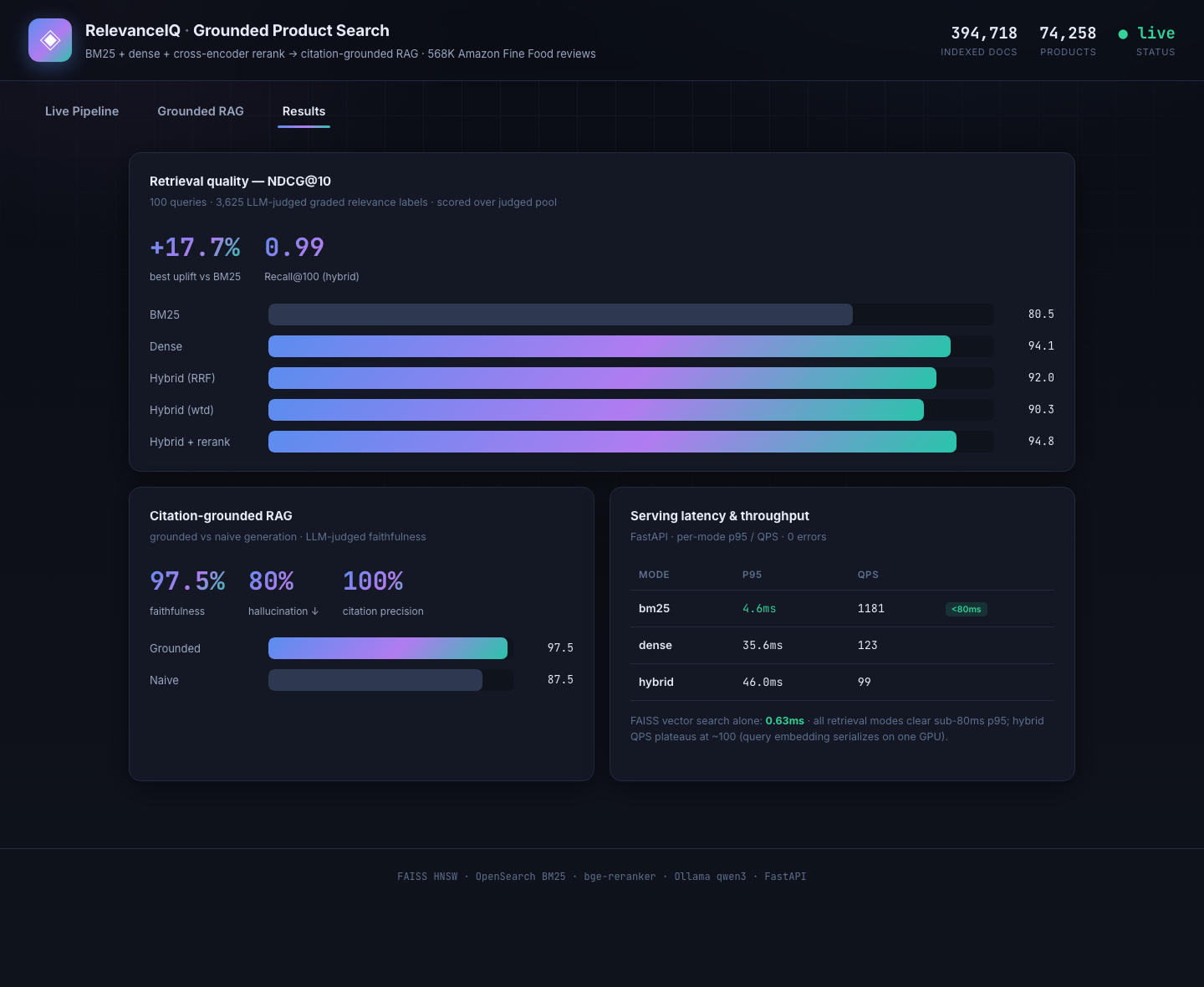
Hybrid retrieval + reranking: +17.7% NDCG@10 over BM25
| Pipeline | NDCG@10 | Recall@100 | MAP | vs BM25 |
|---|---|---|---|---|
| BM25 (lexical baseline) | 0.805 | 0.661 | 0.622 | — |
| Dense (bge-base) | 0.941 | 0.697 | 0.689 | +16.8% |
| Hybrid (RRF) | 0.920 | 0.994 | 0.963 | +14.2% |
| Hybrid + cross-encoder rerank | 0.948 | 0.994 | 0.978 | +17.7% |
The headline is not just NDCG. Hybrid lifts Recall@100 from 0.66 to 0.99. BM25 alone misses a third of relevant reviews that dense retrieval catches. Fusion plus reranking wins on precision and recall at the same time.
Citation-grounded RAG: 80% fewer hallucinations
| Metric | Naive RAG | Grounded RAG |
|---|---|---|
| Faithfulness (LLM-judged) | 87.5% | 97.5% |
| Citation precision | — | 100% |
Grounding uses query reformulation, mandatory [doc_id] citations, and post-hoc validation that drops uncited claims. That cuts the unfaithful-answer rate from 12.5% to 2.5%, an 80% relative reduction, while every citation points to a genuinely retrieved document.
Serving latency: sub-80ms p95 hybrid retrieval
Warm, measured under load (concurrency 4, 300 requests/mode):
| Mode | p95 latency | sustained QPS |
|---|---|---|
| BM25 (lexical) | 4.6ms | 1,181 |
| Dense (bge-base + FAISS) | 35.6ms | 123 |
| Hybrid (BM25 + dense + RRF) | 46ms | 99 |
| + cross-encoder rerank | ~670ms | — |
| End-to-end RAG (retrieve → rerank → generate) | ~5.7s | — |
Honest latency framing: FAISS HNSW vector search alone is 0.63ms. The index is never the bottleneck. Hybrid throughput plateaus at ~100 QPS because query embedding serializes on a single laptop GPU (MPS), while BM25 sustains over 1,000 QPS with no GPU step. The full end-to-end RAG path is ~5.7s, almost entirely local LLM generation; retrieval is ~56ms of it.
Architecture
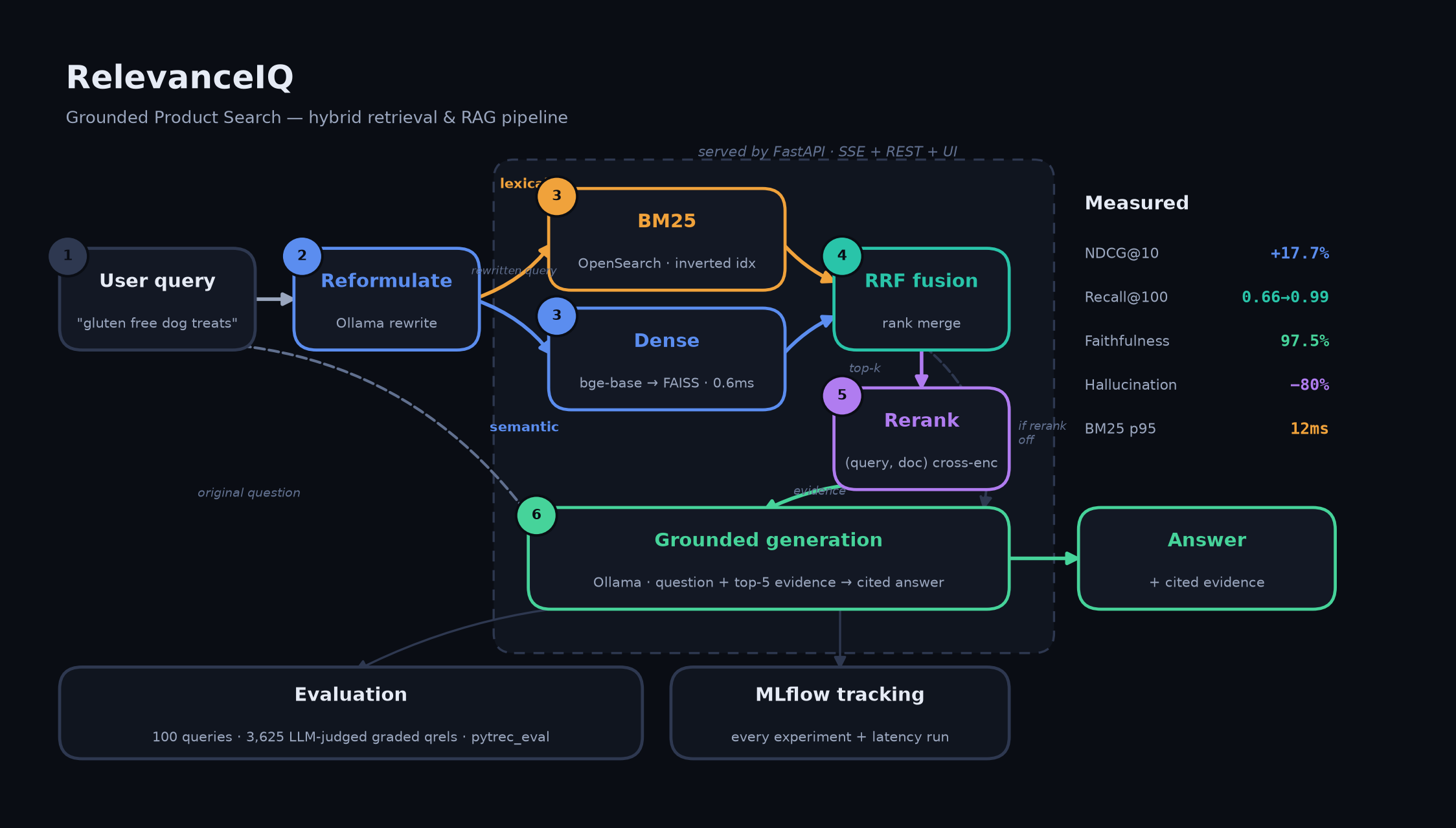
| Layer | Choice | Why |
|---|---|---|
| Lexical | OpenSearch 2.17 BM25 | Battle-tested inverted index, exact term matching |
| Dense | bge-base-en-v1.5 (768-d) + FAISS HNSW | Strong semantic recall; sub-ms ANN search |
| Fusion | Reciprocal Rank Fusion | Scale-free, robust, no tuning needed |
| Rerank | bge-reranker-base cross-encoder | Joint (query, doc) scoring for top-k precision |
| LLM | Ollama qwen3:8b | Local; reasoning off for eval (14× faster), on for answers |
| Eval | pytrec_eval + LLM-judged graded relevance | Rigorous IR metrics without human labels |
| Serving | FastAPI + Uvicorn · MLflow | One-process serving; full experiment provenance |
1
2
Query → reformulation → parallel BM25 + dense retrieval → RRF fusion
→ cross-encoder rerank → grounded generation → citation validation → cited answer
Interactive UI
A dependency-free web app (no build step) that makes the pipeline legible. Run make serve and open http://127.0.0.1:8000/.
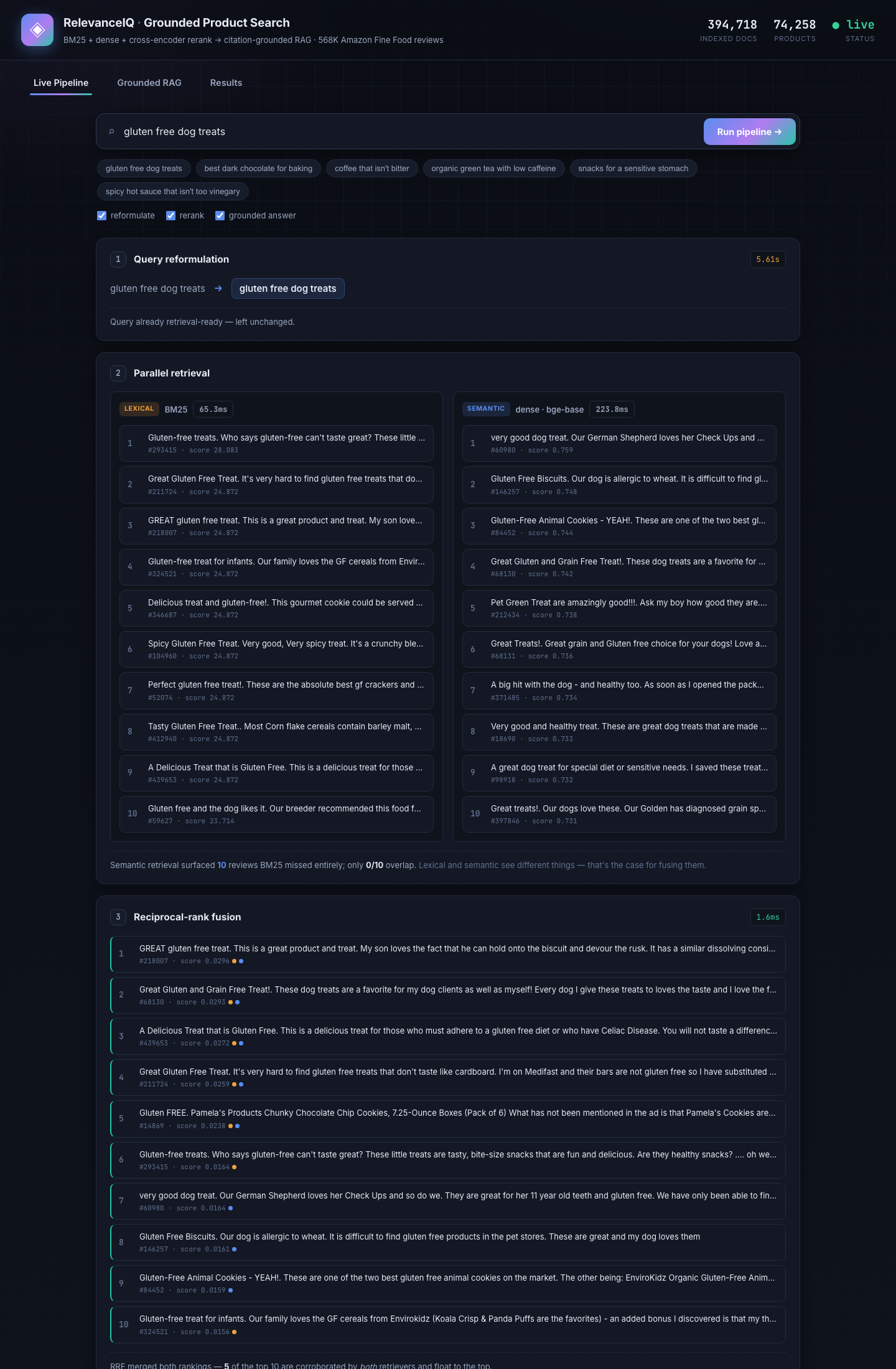
- Live progress — each stage shows real latency as it runs
- Side-by-side retrieval — see which reviews lexical found that semantic did not, and vice versa
- Rank-change deltas — watch the cross-encoder pull a review from rank #9 to #1
- Grounded answer — types out with clickable citations; click any hit to read the full review
Three tabs: Live Pipeline · Grounded RAG · Results dashboard
Engineering That Holds Up
Built to survive failure, not just demo once:
- Resumable jobs — embedding, query generation, LLM judging, and RAG eval checkpoint to append-only JSONL and skip completed work on restart
- Retry with backoff — external calls never silently corrupt a result; MLflow degrades to a no-op if the server is down
- Honest evaluation — NDCG is scored over the judged pool; limitations are documented, not omitted
28 modules · ~2,800 lines of Python · 11 tests · zero absolute paths · fully self-contained.
Corpus vs. index counts: the raw corpus is 568,454 reviews. After removing exact duplicate
(user, text)reviews, 394,718 unique reviews are indexed. Both numbers are reported honestly throughout.
Getting Started
Prerequisites: Python 3.11, Docker, Ollama (ollama pull qwen3:8b). Everything runs locally.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
git clone https://github.com/AbhijitMore/relevanceiq.git
cd relevanceiq
uv venv --python 3.11 .venv && uv sync
make up # OpenSearch + MLflow
make verify # preflight checks
make download # fetch dataset (568,454 rows)
make ingest # clean + dedup → parquet
make index # BM25 bulk index + FAISS HNSW
make eval-set # 100 queries + LLM-judged qrels
make eval # NDCG@10 / Recall@100 / MRR / MAP
make rag # naive vs grounded faithfulness eval
make serve # FastAPI + UI
make bench # p50/p95/p99 latency + QPS
make test # 11 unit tests
Limitations
- LLM-judged relevance approximates human labels; relative gaps between methods are the trustworthy signal
- Single laptop setup; production would use managed OpenSearch, GPU embedding/reranking, and sharded vector stores
- Local LLM generation (
qwen3:8b); the grounding mechanism and its measured 80% hallucination reduction are model-agnostic
Links
- Repository: github.com/AbhijitMore/relevanceiq
- Reproducibility: REPRODUCE.md
- Dataset: Amazon Fine Food Reviews (Stanford SNAP)
Contributions and feedback are welcome.